 |
||
咨询QQ: 杂志订阅 编辑 网管 培训班 市场部 发行部 杂志订阅 编辑 网管 培训班 市场部 发行部电话服务:  010-82024981 010-82024981 | ||
 |
||


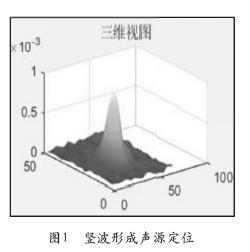

2.1部署方案
基于现有声纹设备,可采用端、边、云一体的方案架构,前端传感器集成声纹传感器,非侵入式安装,采集设备运行的声纹数据,通过有线/无线方式传输给边缘计算网关,边缘计算网关内置基于深度学习架构的设备运行状态判断(检测)算法模型,对数据进行初步处理,并将设备运行异常的相关数据上传服务器(支持公有云/私有云/本地部署),服务器运行故障检测和故障预警大模型,对设备运行状态进行监控,实时告警具体故障,并对故障趋势做预警判断,有效保证被监测设备的安全、稳定运行。
2.2采集器选择
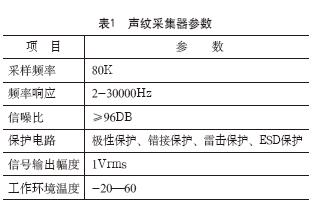
在选用采集器时,应根据数据中心的实际情况进行选择,如水泵冷机等噪音较大的设备,应选用与之匹配的采集器,如下声纹采集器参数推荐见表1。
2.3算法模型
在算法模型上,可采用使用基于Transformer模型的算法进行设备运行状态分析和故障判断,算法状态定义如下:
正常状态:机器运行状态较好,没有明显的故障或异常,处于正常工作状态。
普通状态:机器运行状态较好,可能存在一些轻微的问题或不寻常的运行状况,但尚未达到需要紧急处理的程度。
故障状态:机器处于报警状态,需要关注可能的故障情况。具体的故障包括转子不平衡、转子不对中、转轴弯曲、联轴器故障、转子裂纹、支座松动、油膜涡动。故障状态表明机器存在一些问题,但尚未到达需要立即停机或进行紧急维修的程度。此时,可以进行更详细的诊断和监测,以确定具体的故障原因。
高危状态:需要人工介入的状态,表明机器可能处于严重的故障或危险状态,需要立即停机并进行人工检查、维修或处理。高危状态可能对设备的安全性和性能产生重大影响,需要迅速采取行动以防止进一步损坏或事故发生。
2.4 损失函数设计:
损失函数应考虑故障预测准确率和检出率,可以使用二分类交叉熵损失函数或其他适当的损失函数。损失函数的设计应重点关注模型对故障状态的准确识别,以最小化误报和漏报。
Transformer学习模型的构建、训练和优化:
选择适当的Transformer学习算法,如BERT、GPT等,根据当前状态数据训练模型。
使用设计好的损失函数进行模型训练,并根据验证集的表现进行优化,可以使用梯度下降等优化算法。
考虑使用预训练的Transformer模型,在特定任务上进行微调,以提高模型的性能。
2.5部署和应用:
在训练完成后,将优化后的学习模型部署到实际的数据中心运转设备监测系统中,模型将根据当前状态和学到的策略选择最佳的动作,以实现节能的目标,监控模型的性能,并定期更新模型以适应可能发生的新情况,整个流程需要综合考虑模型的准确性、泛化性能以及实际应用中的可解释性和可操作性。同时,对于机器状态的定义、损失函数设计以及模型的选择,需要根据具体的应用场景和数据特点进行调整和优化。
2.6部署原则:
在设备早期部署的同时,也需要根据现场对新技术的要求,结合数据中心实际需求,注意循以下原则:
1)要采用非侵入式数据采集,避免与动环系统冲突:通过磁吸方式加装传感器,实时采集设备的声纹数据,无需接入原有的系统,不影响正常的业务逻辑和功能,实时监测设备运行状态,提前感知设备异常和异常趋势,实现智慧监测,线缆利用已有桥架走线,确保美观;
2)注意进行AI智能识别学习:边缘计算网关和本地服务器分别运行智能监测和故障预警AI算法模型,不断优化,有效保证故障告警和预警准确性,有效提升设备运维管理的自动化和智能化水平;
3)私有化部署:为了确保数据安全,满足数据中心信息安全的相关要求,算法模型和应用系统均部署在数据中心本地,数据通过内网进行传输。
三、结论
综上,声纹系统在数据中心的创新与结合,采用声纹识别技术,结合AI大模型,与传统定时、定点巡检相比,灵活部署,可实现24小时在线监测,提前获取设备运行的异常状态,早期预防,避免停机事故的发生,降低设备运维成本,节约维护时间,以创新功能和数字化,智能化技术推动运转设备在线监测和故障预警更加有效。围绕数据中心旋转类设备设计,与传统定时巡检和维护相比,更注重实时监测,故障告警,设备健康分析和故障预警一体化解决方案,同时结合人工智能技术,实现AI设备故障诊断、AI设备健康状态监测、AI设备故障预警等高级功能,将是一项新的数据中心智能早期报警的解决方案。
编辑:Harris

